Introducing MCAPI
I recently wrote about a “multi-core” development project that I worked on many years ago, including some details of how we managed communication between the CPUs. Things have moved on a lot since those days and multi-core is now rapidly becoming the norm in embedded designs. It is, therefore, unsurprising that a degree of standardization is being established.
Specifically, the Multicore Association [MCA] have defined MCAPI, which is gaining popularity. Mentor Graphics have just announced support for this standard.
I thought it would be worth looking into …
In an AMP (asymmetric multiprocessing) system, each core may have a different CPU architecture and may be running a different operating system [or no OS at all]. A separate layer of software is needed to facilitate communication between the cores. This is the role of MCAPI.
MCAPI is basically a communications API, similar to the familiar sockets API used in networking. An application uses standardized function calls to send and receive data to and from any core in the system. The MCA added some further APIs for managing data endpoints and gathering other information, bringing the total function count to 43. The specification does not dictate how data is physically transferred; i.e., shared memory, Ethernet, etc. It specifies only the user’s API level expectations when executing the respective routines.
Some IPC protocols require a full TCP/IP stack to exchange data, creating a bloated memory footprint. MCAPI, on the other hand, does not require TCP/IP and is much more lightweight. Another major benefit of MCAPI is scalability at the application level. As more threads are added and additional communication points required, transactions are handled seamlessly through the use of the MCAPI primitives. Furthermore, MCAPI provides a reliable interface for data transfer, ensuring data is delivered as expected by the application.
In the most basic MCAPI model, each core is represented as an individual “node” in the system. When a node needs to communicate with another node, it creates an endpoint for sending or receiving data – very similar to a TCP/IP socket. MCAPI primitives are then used to issue calls to send or receive data on the endpoint, and the underlying hardware driver moves the data accordingly.
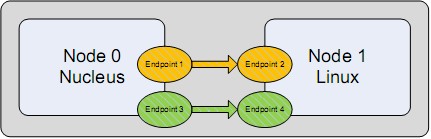
In this example, Node 0 is running Nucleus, and Node 1 is running Linux. Endpoints 1 and 2 send and receive one stream of data. Endpoints 3 and 4 send and receive other data quite independently. Under the hood, data may be transmitted via the shared memory driver using internally managed buffers. This interrupt-driven method ensures that each buffer transmitted will be received in the proper order and delivered to the application for processing.
This implementation is much more scalable than a “roll your own” approach. If additional threads need to send or receive data across cores, they create a new endpoint and go about their business. The implementation is also more reliable, as each buffer that is transmitted will be received in a predictable order.
Thanks to my colleague Tammy Leino for her guidance on this topic.
Comments
Leave a Reply
You must be logged in to post a comment.
I beleive there is already a interrupt mechanism available called IPI (inter processor interrupt) which can be used to communicate between cores
kavi,
You are correct and the Mentor MCAPI implementation makes use of IPI to initiate data transfer.
The value of Mentor MCAPI is a fast, lightweight IPC mechanism with a standardized API across OSes, transports(shared memory, RIO, etc), and targets(PPC, ARM, MIPS, etc).
James Parker
Product Manager, Multi-OS on Multicore
Colin,
Is it possible to designate a selected core for one, and only one process? For example, on a PC dedicate one of the cores to do the real-time stuff, and not worry about Windows or Linux stealing processor cycles unexpectedly?
“gilbert.ross@gmail.com”
Gil: There is no reason why every core in a multicore system has to run an OS at all. If you want a single process/task to run, perhaps an OS would be redundant.