How Digital Twins Help Scale Up Industrial Robotics AI

Part 1: Commissioning a vision-based Supervised Learning solution
Artificial Intelligence (AI) and Machine Learning (ML) are technologies which enable robots to perform many tasks they could not have done before. However, building, validating and deploying these technologies for industrial robotic systems is a big challenge. This is the first in a series of posts about how digital twins of the factory equipment and product can help ease the pains of deploying Artificial Intelligence and Machine Learning methods in industrial robotics.
The Promise of AI for Industrial Robotics
As a part of the Artificial Intelligence and Machine Learning revolution, today robots can make real-time decisions based on inputs such as cameras (2 or 3 dimensional), force/torque sensors and LiDARs. This enables robots to perform industrial tasks that before could only be performed by humans such as part/product detection, random part grasping, assembly, wiring and so on.
Machine learning algorithms such as artificial deep neural networks, are the “brains” behind these complex robotic skills. Contrary to traditional programming, a machine learning algorithm is not programmed, rather it is trained for specific tasks by providing it with good examples of the task outcome.
The Challenges of Commissioning Autonomous Industrial Robots
Training the machine learning algorithms which enable these robotic skills is laborious and time-consuming. It requires setting up an environment where robots, sensors and other peripheral equipment are all integrated. Moreover, the task for which the robots are training must be attempted many times in order to generate enough training examples. Often, manual assistance is required to position the parts after every try and monitor each of the tasks executed by the robot in order to provide the correct feedback – success or failure. It is also frequently required to stop the robot in case there is a safety issue or a risk of damaging the product or equipment.
To explain this point further, consider this simplified example. An automated process where a robot picks parts from a bin while a camera is positioned on top of the bin to capture images of its interior.

A robot picking parts from a bin based on camera input.
In order to make this process work, a machine learning algorithm is trained to detect the position and dimension of the parts from images captured by the camera. The algorithm is trained by supplying it examples, i.e., camera images. For each image, accurate information about the part position and dimensions must be manually supplied by, e.g., drawing a bounding rectangle around the parts. Machine learning algorithms become robust after they are trained with enough (usually tons of) training examples, so given the bin-picking example – parts must be manually placed inside the bin in many different configurations. For each configuration, an image must be captured by the camera, and the parts position and dimension are annotated. This is a lengthy, cumbersome and expensive process.

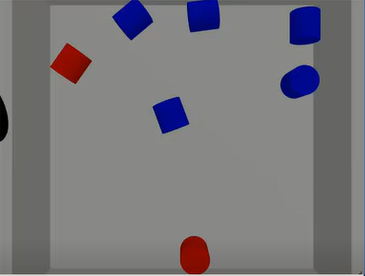

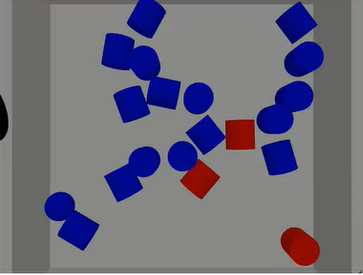
The machine learning method described here is an example of Supervised Learning. When training a supervised learning algorithm, the training data will consist of inputs (e.g., images), paired with the correct outputs like bounding rectangle, textual labels describing the objects in the image (“box”, ”can”, ”screw”), object color and so on.
However, training a machine learning algorithm to detect objects in an image is only the beginning. The complete system – robot, camera and ML algorithm, all need to be integrated. This means that the task must be attempted for multiple cycles to validate that the robot handles it robustly without damaging the parts or colliding with the sides of the bin. Often an equipment modification is required, one which incurs additional costs and delays. For example, a conclusion that a gripper must be replaced or customized might only be reached after all the other pieces of equipment are assembled and integrated (robot, bin, camera, controller, etc.). Such a process can take weeks and even months to converge into a robust automation solution, depending on the task and system complexity. Moreover, some of the system components might still not be available or utilized in production already, which limits or even prevents your access to them for the purpose of training and integration.
The Role of Digital Twins
A digital twin is a virtual representation of a physical product or process, used to understand and predict the physical counterpart’s performance characteristics. Digital twins are used throughout the product lifecycle to simulate, predict, and optimize the product and production system before investing in physical prototypes and assets.
By utilizing the digital twin of the production system and the product it is now possible to significantly shorten the time taken to setup and validate a robotic system with integrated vision and machine learning. Thus, you can achieve robust and reliable results faster and at much lower costs.
In a virtual environment the real robot, parts and camera are replaced with virtual ones. Instead of spending a lot of time and resources on setting up the equipment, capturing many images and manually annotating them it is now possible to do so easily and automatically within a virtual environment. The next step is to switch from virtual to physical – the real equipment is set up and integrated. The ML algorithm might require some additional training with images captured from the real camera. However, since the ML algorithm is already pre-trained in the digital twin, it will require significantly less real sample images to achieve an accurate and robust result, hence it will reduce the physical commissioning time, resources and re-work.
Tecnomatix Process Simulate Robotics AI Tools
Tecnomatix Process Simulate is a robotics and automation programming and simulation software by Siemens. The tool addresses multiple levels of robot simulation and workstation development, from single-robot stations to complete production lines and zones.

Process Simulate is widely used by many customers throughout the world to plan, simulate and validate automated production, and now it also supports tools and APIs which enable virtual setup and training of vision systems and ML algorithms.
Watch this video tutorial on how to set up a virtual RGBD (3D) camera and use it to automatically generate images and labels for training a Machine Learning algorithm:
Code examples shown in the videos will follow shortly and we will update the links in this blog once they are available.
In the next post I will be covering Reinforcement Learning, a different Machine Learning method. I will discuss its role in robotics and how you can accelerate it by using simulation.
Liked this post? please comment and share!
Siemens – where today meets tomorrow!


![Automation World features Tecnomatix Process Simulate: the essential software for virtual commissioning [ARTICLE]](https://blogs.stage.sw.siemens.com/wp-content/uploads/sites/7/2024/03/automation-world-process-simulate-2-395x222.png)
Comments